 |
 |
|
|








| Object
Representation
[back] In everyday life, people categorize objects so easily that they do not realize how complex this task is. Objects from the same category are very different from one another. Even the same object never projects the exact same image to the retina, because of changes in the surrounding illumination, the particular viewpoint from which the person is looking at the object, how close the person is to the object, etc. Furthermore, we are capable of extracting different forms of categorical information from the same objects, depending on environmental demands (e.g., from a single face we can extract information about age, gender, race, etc.). How are faces and other objects encoded in the brain? Visual processing in the brain results in a re-description of the sensory input in terms of a number of "high-level" object properties. Much effort has been dedicated to understanding which object properties are represented "independently" or “separably” from other properties, and which properties are represented in a more "holistic" or “integral” manner. Given that most researchers agree on the importance of this distinction between separable and integral object properties, it is surprising how little effort has been dedicated to improve the way in which these concepts are tested and measured. By far the most common approach is to use operational definitions of independence, which are linked to rather vague conceptual definitions. A disadvantage of this approach is that different researchers use different operational definitions, often leading to contradictory conclusions. General recognition theory (GRT; Ashby & Soto, 2015) is a multidimensional extension of signal detection theory that has solved such problems in psychophysics, by providing a unified theoretical framework in which different forms of independence can be defined and linked to operational tests. An important line of research in our lab has extended GRT to allow the study of dimensional separability through a variety of behavioral and neuroimaging tests, all linked within a coherent framework. Our first step in this direction was the development of GRT with Individual Differences (GRT-wIND; Soto et al., 2015; Soto & Ashby; 2015), an extension of GRT that allows a better dissociation between perceptual and decisional forms of separability than traditional models. These advances in GRT have been accompanied by the development of a user-friendly R package (grtools; see Soto et al., 2017), which allows scientists without a computational background to easily apply GRT-wIND and other GRT analyses in their own research. 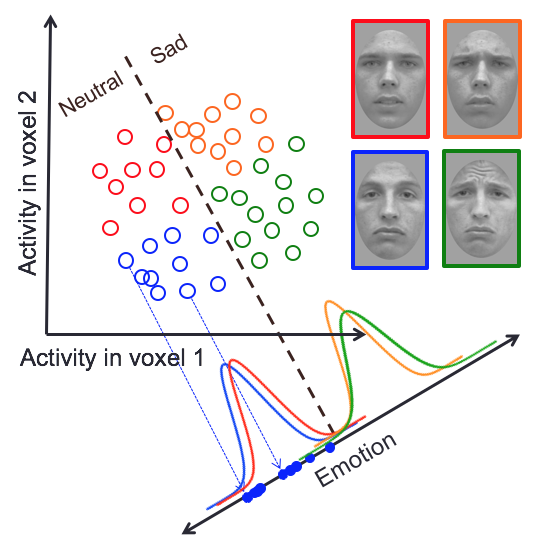 Our second step has been to extend GRT to study the separability of brain representations through neuroimaging. We have accomplished this by linking GRT to neural encoding m odels from computational neuroscience (Soto, Vucovich, & Ashby, 2018; see also Ashby & Soto, 2016). The resulting theoretical framework allowed us, for the first time, to link behavioral and brain measures of separability. Unlike previous approaches, our framework formally specifies the relation between these different levels of perceptual and brain representation, providing the to ols for a truly integrative research approach in the study of dimensional independence. We are currently working on validating this extended framework and applying it to the study of face dimensions. How does learning about objects influence their neural encoding? We have developed a Bayesian theory of generalization (Soto, Gershman, & Niv, 2014; Soto et al., 2015) proposing that separable dimensions exist mostly because they allow easy classification of natural objects. This suggests that category learning itself might influence the way in which objects are encoded, facilitating their representation in terms of independent dimensions that have been useful for categorization in the past. In line with this idea, we have shown that although unfamiliar morphed face dimensions are non-separable (i.e., integral), extensive categorization training with stimuli varying in such dimensions makes them more psychologically privileged and increases their separability (Soto & Ashby; 2015). Relatedly, categorization training makes object recognition more independent to changes in viewpoint (Soto & Wasserman; 2016). We have used reverse correlation and visual adaptation techniques to more precisely characterize how categorization training influences the visual representation of face identity (Soto, 2018). We are currently performing an fMRI experiment aimed at determining how the neural representation of face identity changes with categorization training. We will analyze the data from this experiment using both traditional multivariate analyses and our own GRT tests of neural separability. Learning about the reward value or emotional valence of objects can also influence their neural representation. For example, attention is automatically biased towards visual stimuli and properties that predict positive feedback or reward. Neurophysiological and neuroimaging data suggest that the tail of the caudate could be the site where learning of such reward-driven attentional biases is implemented. We have recently proposed a neurocomputational model suggesting that learning of associations between visual representations and rewards in the caudate may influence those same visual representations via closed loops involving visual cortex and the basal ganglia. The model can explain the basic behavioral effect of value-based attentional capture, and we are currently working on simulating related neurophysiological and behavioral phenomena. This model also makes specific predictions about how reward learning should change the encoding of the rewarded and unrewarded stimuli, which we expect to test in the near future. Do depression and anxiety influence face encoding? 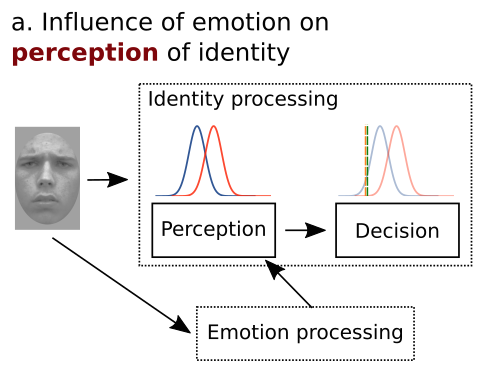 |